
Performance experiments
Posted Sep 28 2015 by Florian WeschGetting the most out of the Raspberry PI is one of the top priorities for info-beamer. Not all improvements work as expected. This blog post shows three examples.
Faster texture loading on the PI
OpenGL is used in info-beamer for drawing images, videos and fonts on the screen. To use OpenGL, info-beamer creates an OpenGL rendering context. It can then upload textures to that context and draw them on the screen.
Image loading in info-beamer is done in a background thread, so the rendering loop can happily draw at 60 frames per second in the main thread while the image is loaded in the background.
Well. Almost. With one exception: An OpenGL context can only be used from a single thread at the same time. Before using any OpenGL related function, like those that upload decoded image data into a texture on the GPU, the thread that wants to use those functions has to be made current. An OpenGL context can only be current in a single thread. This also implies that the main thread has to stop using OpenGL while a background thread uploads image data.
After a frame was drawn in info-beamer, the main threads checks if there is any background thread that requests exclusive access to the OpenGL context. If that is the case it temporarily gives up the context. The background thread can then grab the now available context and upload texture data. Once that's done it hands back the context to the main thread.
For big images, uploading the texture can be expensive. For a 1920×1080 RGB image this takes around 70ms. This results in a noticable pause while rendering since this operation happens in the main thread. At 60 frames per second this results in 3-4 frames skipped. If you have scrolling text this is noticable.
Let's try to improve this.
Using two OpenGL contexts
The first approach is to use two different GL contexts. One that is exclusively used by the main rendering thread. And a second context that is shared by all background threads and is available for them on request. See here and here.
When creating a new context it is possible to specify that it should share resources with an existing context.
background_context = eglCreateContext(
display, config, context, context_attributes
);This context can then be made current in background threads. Since textures are shared with the main context their names can be used across both contexts.
So in theory the texture can be loaded completely independent from the main thread by doing the following steps in a background thread:
- Load image data in memory
- Acquire exclusive access to the background context
- Submit image data using glTexImage2D
- Release access to background context
At this point the image is available to OpenGL and can be drawn in the rendering thread.
Unfortunately these steps didn't have the expected result. Despite using the second background context there is still a noticable pause in the rendering thread. It seems that there is still some exclusive access to some resource required.
Using EGLImageKHR
Another possible solution is similar: It also uses two contexts. But they don't even have to be able to share anything: Using EGLImageKHR it is possible to create handles to image data and use those handles later in another context to associate uploaded image with a texture using glEGLImageTargetTexture2DOES. See here for some example code.
The results are very similar to the first idea: Allocating the texture and uploading it still stalls the main rendering thread despite not using its context at all.
You might even get away with a slow texture upload by splitting it into multiple parts using glTexSubImage2D. But then allocating a 1920×1080 texture still costs about 35ms.
GLuint tex; glGenTextures(1, &tex); glBindTexture0IB(tex); // this call takes 35ms... glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 1920, 1080, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);
I guess it's not that easy after all.
Using OMX to decode JPEGs
Previous experiments were mostly file format independant since the file was decoded into a malloc'ed buffer using different software decoders (using libjpeg-turbo or libpng) and then uploaded.
The PI can use a hardware decoder to decode JPEG or PNG images. Although it might be tricky from time to time.
To use hardware decoding on the PI you have to use OMX. It's an API that allows you to connect components together that to form a pipeline. Decoding JPEGs involves two components: An image_decode component that decodes the compressed JPEG data into some intermediate format. And the egl_render component that uploads this intermediate format into an OpenGL texture. All components are hardware accelerated on the PI. The setup looks like this:
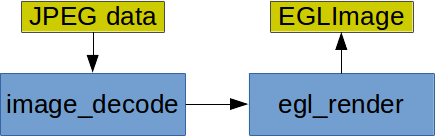
Using OMX is a bit tricky since the API is asynchronous: You submit buffers to the image_decode component and later get a callback in a different thread that notifies you that the image data was decoded. And you have to submit an EGLImage (see previous experiment) to the egl_render component and get notified once the texture was filled.
The problem with this approach is that the EGLImage the egl_render component fills has to be bound to an OpenGL texture of the correct size. So the texture has to be preallocated using glTexImage2D, which brings us back to the previous experiment and the 35ms delay. Using hardware decoding seems like a good idea. But it doesn't solve the problem.
Epilog
All three experiments have failed to achieve a noticable improvement. I'll definitely look into this problem again. I'm sure there's some better way to load large images without visible delay. One idea might be to look into other ways of transferring pixels between threads. There is an interesting compositing example which maps a complete GL surface into an EGLImage.
Right now image loading for all image types is split up between allocating the texture and uploading texture data. Texture uploading might be solvable by using glTexSubImage2D to upload a single texture across multiple frames by splitting the upload into multiple parts.
This still leaves the allocating part unsolved. It might be possible to incrementally allocate memory by calling glTexImage2D repeatedly with incrementing sizes:
GLuint tex; glGenTextures(1, &tex); glBindTexture0IB(tex); // These 3 calls only take 6ms. why? glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 512, 512, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL); glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 1024, 1024, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL); glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 1920, 1080, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);
For some reason that seems to help, even when calling glTexImage2D immediately without releasing the context. But that feels wrong and smells like it would potentially fragment GPU memory.
It might also be possible to do faster uploads by using ETC1 compressed textures. But this would result in a fairly expensive step to convert images before uploading them. It also results in a slightly decreased image quality.
A final idea might be to only use the egl_render OMX component to upload texture data. I guess it should be possible by feeding it the correct input data, but I didn't test that yet.
If you read this far and have any ideas, I'd be happy to hear them. Please get in contact or comment on this forum post.
Read more...
Recent blog posts
info-beamer hosted 16 releasedinfo-beamer hosted 15 released
info-beamer hosted 14 released
info-beamer hosted 13 released
More blog posts...
Learn more about info-beamer.com
The info-beamer hosted digital signage platformThe info-beamer pi software
Sign up to info-beamer hosted

info-beamer.com offers the most advanced digital signage platform for the Raspberry Pi. Fully hosted, programmable and easy to use. Learn more...
Get started for free!
Trying out the best digital signage solution for the Raspberry Pi is totally free: Use one device and 1GB of storage completely free of charge. No credit card required.
Follow @infobeamer on Mastodon to get notified of new blog posts and other related info-beamer news. It's very low traffic so just give it a try.
You can also subscribe to the
![]() RSS feed.
RSS feed.
Questions or comments?
Get in contact!
